
Dlaczego trzymać wszystkie zdarzenia w jednej tabeli?
Cześć!
Każdy z nas ma swoje rzeczy, których się boi. Asterix bał się, że niebo mu spadnie na głowę. Sporo z nas boi się piątkowych wdrożeń na produkcji. Każdy kto usłyszy, że w systemie Event Sourcing trzyma się wszystkie zdarzenia w jednej tabeli wygląda na przerażonego. “Eee, ale jak to?“.
Przypomnijmy sobie jak wygląda nasz przykładowy SQL tworzący tabelę:

To co jest najważniejsze to:
- stream id - czyli inaczej identyfikator rekordu (odpowiadający id rekordu w klasycznej tabeli),
- data - zserializowane do JSON dane zdarzenia,
- version - reprezentujący wersję strumienia (rekordu(), dla którego zaszło zdarzenie. Numerowany dla każdego rekordu osobno. Pierwsze zdarzenie (np. ReservationCreated) będzie miało numer 2, drugie (np. ReservationSeatChanged) będzie miało numer 3, itd.
Przykład jak mogłyby wyglądać dane w tej tabeli:
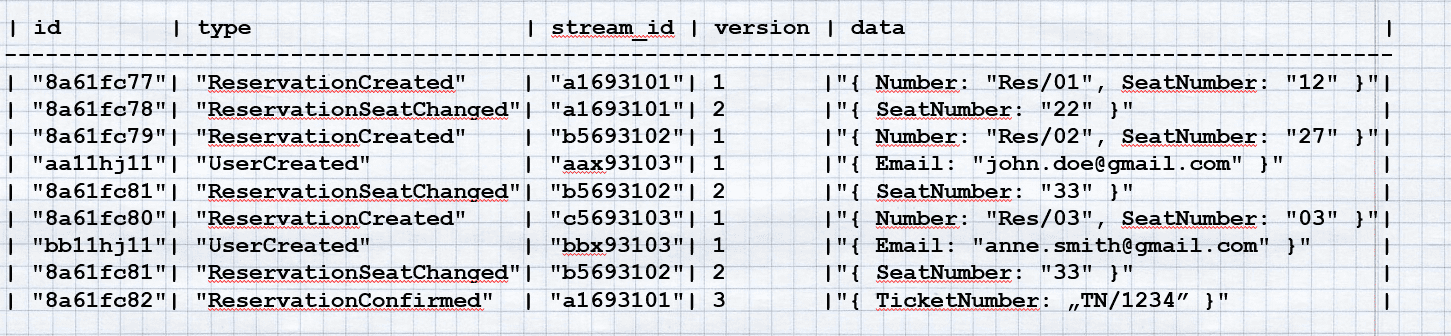
Zauważ wymieszane zdarzenia rezerwacji i użytkowników. Co więcej zdarzenia w ramach rezerwacji przeplatają się ze sobą. Burdel? No właśnie nie do końca. Pozwól, że zaznaczę Ci pewne wpisy.
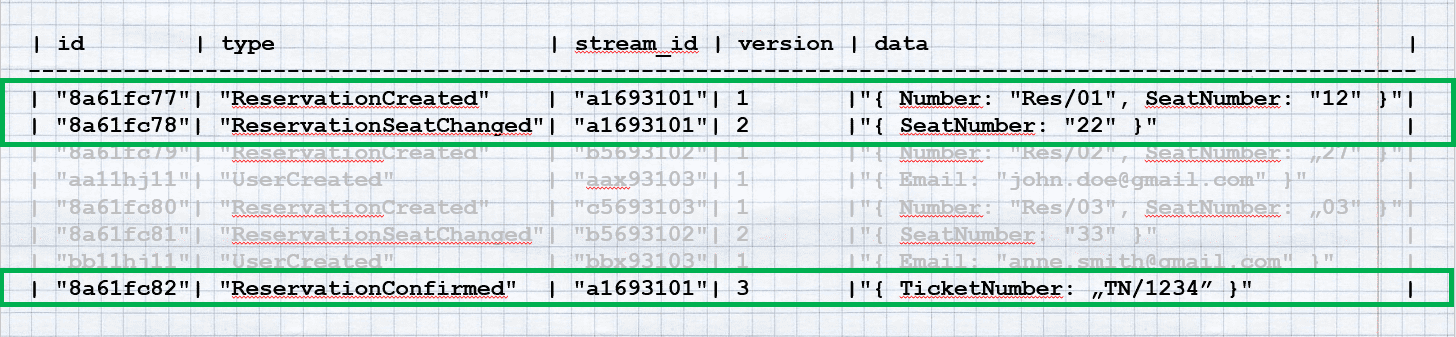
Zaznaczyłem Ci zdarzenia dla jednego strumienia (rekordu). Tak właśnie działa Event Store gdy odbudowuje stan agregatu. Pobiera zdarzenia dla danego strumienia, sortuje je według kolumny version i następnie aplikuje jeden po drugim odbudowując stan naszego obiektu.
Jeśli przypatrzysz się jeszcze raz tabelce to zauważysz, że tak naprawdę mamy dwie kolejności:
- kolejność rekordów, która reprezentuje globalną kolejność zdarzeń w jakiej zaszły one w systemie (uwaga: z racji, że tabele same w sobie nie gwarantują kolejności rekordów - dla pewności można dorzucić pole z globalną sekwencją - tak jest robione w Marten),
- kolejność w ramach strumienia (innymi słowy - dla rekordu) reprezentowaną przez kolumnę version.
No i teraz po co nam jest jedna tabela? Po to, żebyśmy byli w stanie zagwarantować globalną kolejność zdarzeń w systemie. Czy trzymanie wszystkich zdarzeń w jednej tabeli to problem? Powinienem powiedzieć po konsultancku “to zależy”.
Zanim sobie odpowiemy na to pytanie zadaj sobie pytanie ile operacji dzieje się dziennie w Twoim systemie? Podpowiem:
- 10 tysięcy operacji dziennie to rocznie 3,65 miliona rekordów,
- 100 tysięcy operacji dziennie to 36,5 miliona rekordów,
- 1 milion operacji dziennie to 365 milionów rekordów.
Powiem tak - 36.5 miliona rekordów to dla bazy relacyjnej to nie jest wielka liczba. 365 milionów to już może odczuć. Jeżeli mamy odpowiednio poindeksowane wpisy (a mamy, bo wystarczy zrobić indeks po stream_id i version bo po tym wybieramy rekordy) to zapytanie będzie bardzo szybkie. Dodatkowo nasze zdarzenia tylko dodajemy, nie modyfikujemy ich, więc log bazy danych nie będzie rósł równie szybko jak w przypadku klasycznych tabel.
Jeżeli dalej obawiasz się, że tabela będzie za duża to mam dla Ciebie na koniecniespodziankę!
Zacząłem pracować nad udostępnieniem archiwum mojego Newslettera. Tutaj polecę Ci 2 wpisy:
- “Jak zoptymalizować Event Store przy pomocy partycjonowania tabel” - https://oskar-dudycz.netlify.app/pl/optymalizacja_event_store_przez_partycjonowanie/
- “Fixy na produkcji i jak (nie) wersjonować zdarzenia” - https://oskar-dudycz.netlify.app/pl/fixy_na_produkcji/
Dostęp póki co publiczny, bo strona w przygotowaniu. Wpisy archiwalne też przybywają stopniowo.
Docelowo będzie dostęp tylko dla zapisanych na Newsletter. Możesz podesłać znajomym i zachęcić ich do zapisu na Newsletter. Oczywiście jeśli uważasz, że warto.
Warto?
Pozdrawiam!
Oskar
p.s. Strona jest “under construction” - trochę w niej grzebię, więc jakby coś chwilowo nie działało to z góry przepraszam.
p.s.2. Za około 2 tygodnie będę miał jeszcze lepsze newsy!