
Jak zoptymalizować Event Store przy pomocy partycjonowania tabel
Cześć!
Witam w kolejnym tygodniu! Dzień coraz krótszy, więcej czasu na lekturę - np. newslettera.
Zacznę tym razem od autoreklamy, chociaż to może za dużo powiedziane, raczej zaproszenia. W listopadzie przyprowadzę szturm na Kraków. Zmasowany atak wiedzą o zdarzeniach:
- 16.11 odbędą się moje darmowe warsztaty z Event Sourcing w ramach inicjatywy devWarsztaty. W trakcie warsztatów zbudujemy Event Store, aby zrozumieć zasady działania Event Sourcing od podszewki. Pokazane zostanie kilka praktycznych wzorców pokazujących, że Event Sourcing, nie jest wcale taki straszny. Sama praktyka, dużo kodu, a na koniec wyjaśniony zostanie przykład konkretnej aplikacji opartej na zdarzeniach z użyciem Marten, Kafki oraz ElasticSearch. Warsztaty przeprowadziłem już jakiś czas temu we Wrocławiu, odbiór był pozytywny, z czego się niezmiernie cieszę, postaram się, żeby krakowskie warsztaty wypadły co najmniej nie gorzej.
- 25-26.11 zadebiutuję na konferencji SegFaultConf gdzie zaprezentuję temat “Cienie i blaski Event Driven Design”. W ostatnim czasie Event Driven Design stało się jednym z najpopularniejszych Buzz Words. Podejście to jest pokazywane jako wzorcowe przy tworzeniu nowoczesnych, skalowalnych systemów. Postaram się zabawić w adwokata diabła i pokazać, co w praktyce może pójść nie tak. Przedstawię, że jej użycie może też boleć. Pokażę jak można wylądować z rozproszonym monolitem i opowiem jak się przed tym bronić. Opowiem o tych wszystkich enigmatycznych terminach jak idempotency, eventual consistency, at least once delivery itd. Obalę kilka mitów i przedstawię sporo faktów bez ewangelizacji, ale za to ze sporą dawką zdrowego pragmatyzmu.
Serdecznie zapraszam!
Rozpoczęta przeze mnie idea “Szkoły Event Sourcing” się rozprzestrzenia, to już nie tylko Ebook i materiały na Github, ale też namacalne wydarzenia, jestem podekscytowany!
Myślę o tym, żeby dla osób, które nie będa mogły/chciały wziąć udział w SegFault zrobić darmowy webinar online, jeśli jest to dla Ciebie interesująca idea daj znać i chcesz wziąć udział w czymś takim to daj znać, postaram się wtedy coś takiego zorganizować.
No dobrze, zacząłem od przerwy na reklamę, jak program na Polsacie. Teraz czas wiedzę.
Jedną z rzeczy, której ludzie się bardzo obawiają w przypadku zdarzeń jest to, że tabela z nimi urośnie do astronomicznych rozmiarów co spowoduje, że będzie ona nieużywalna ze względów wydajnościowych. Jest to trochę mit, bo bazy danych nie mają problemów z nawet kilkoma milionami rekordów. Dobrze założony indeks oraz charakter działania Event Store - wyszukiwanie po identyfikatorze strumienia powoduje, że do efektywnego działania wystarczy zwykle dobrze założony indeks (np. na id strumienia plus ewentualnie dacie dodania zdarzenia).
Dla przypomnienia przykładowa tabela ze zdarzeniami wygląda następująco (zapis SQL z Postgresa):
CREATE TABLE events
(
id uuid NOT NULL, -- klucz główny, identyfikator zdarzenia
type varying(500) NOT NULL, -- typ zdarzenia
stream_id uuid, NOT NULL, -- id strumienia
timestamp timestampz, NOT NULL, -- data zdarzenia
data jsonb NOT NULL, -- pozostałe dane zdarzenia zapisane w postaci JSON
CONSTRAINT pk_events PRIMARY KEY (id),
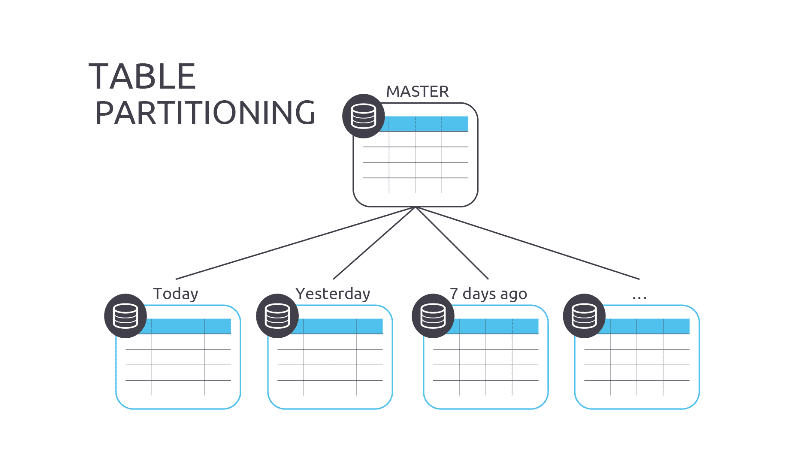
)No dobrze, niby się nie ma czego bać, ale jednak dodanie wpisu do tabeli ze 100 rekordami jest zawsze wolniejsze niż dodanie z 1 000 000 rekordów. Co można z tym zrobić? Do pomocy przychodzi partycjonowanie tabel. Co to jest? Można to porównać do tworzeniu partycji na dysku. Mając np. dysk 500GB możemy go podzielić przykładowo na kilka partycji
- C: - systemowa - 100 GB,
- D: - dokumenty - 50 GB,
- E: - zdjęcia - 150 GB
- F: - filmy - 200 GB
Podział ten jest zarówno fizyczny, bo pliki na partycjach leżą w innych miejscach na dysku, ale też logiczny, bo dzielimy sobie pliki wg pewnej założonej kategori. Dzięki czemu szybciej jesteśmy w stanie znaleźć szukany przez nas plik.
Jak może to pomóc w przypadku zdarzeń? Partycję tabeli możemy wybrać na bazie wartości danych w wybranej kolumnie. Przykładowo możemy zrobić partycję na podstawie typu strumienia - np. zdarzenia dotyczące agregatu User byłyby fizycznie rozdzielone od zdarzeń agregatu Task. Innym modelem partycjonowania i popularniejszym jest partycjonowanie po dacie. Dzięki czemu możemy mieć nowe zdarzenia oddzielone od starszych. Im starsze zdarzenie tym jest większa szansa, że dotyczy nieaktywnego rekordu i nie będzie potrzeby w ogóle je pobierać. Partycje moga zostać “odpięte”. Dzięki temu odpinaniu możemy efektywnie zrobić archiwizację starszych zdarzeń i mocno zmniejszyć liczbę danych w bazie danych. W razie potrzeby można taką odpiętą partycję podpiąć z powrotem.
Dodatkowo mechanizm partycjonowania jest najbardziej efektywny w przypadku tabel, które są “append only” - czyli dokładnie takich jak właśnie zdarzenia, bo tak jak (już) wiem zdarzenia są niezmienialne. Co się wydarzyło już się nie cofnie, a co się zobaczyło już się nie odzobaczy.
Użycie Postgresowego mechanizmu partycjonowania tabel jest moim kolejnym największym wyzwaniem w Martenie. Planuję niedługo zacząć nad nim prace. Jeśli ciekawi Cię co planujemy dodać do naszej Event Sourcingowej części - zerknij tutaj: https://github.com/JasperFx/marten/issues/1307.
Jeśli zaciekawił Cię temat partycjonowania tabel to polecam linki:
- https://severalnines.com/database-blog/how-take-advantage-new-partitioning-features-postgresql-11
- https://medium.com/driven-by-code/postgres-partitioning-in-v10-and-v11-678cdd866d6c
- https://docs.microsoft.com/en-us/sql/relational-databases/partitions/partitioned-tables-and-indexes?view=sql-server-ver15
Chętnie go też rozwinę, jeśli chcesz, żebym o tym napisał - daj znać! Jeśli masz pytania uwagi to również śmiało pisz. Pozdrawiam i życzę udanego tygodnia!
Oskar