
Event-Driven Design to nie Event Sourcing, a Kafka to nie Event Store
Cześć!
Są takie rzeczy, które mnie denerwują. Jeden z moich wykładowców (pan Kaliś) zawsze nam powtarzał, że “inżynier powinien się wypowiadać precyzyjnie”. Właśnie brak precyzyjności mnie często irytuje. Nie tylko u Milika, ale też w IT.
W dyskusjach, które ostatnio prowadziłem na warsztatach czy też na konferencji często się przejawiał temat Event-Driven Design vs Event Sourcing. Te dwa pojęcia są bardzo często mylone - ba! Często używane są zamiennie.
Innym najczęstszym tematem dyskusji jest Kafka. I właśnie Confluent, który nią zarządza i utrzymuje dołożył do tego postrzegania bardzo dużą cegiełkę. W swoim marketingu starają się pozycjonować Kafkę jako narzędzie, w którym można zrobić wszystko co tylko związane ze zdarzeniami. Nie zrozumcie mnie źle, Kafka to super kombajn, jestem jej wielkim fanem, jest to świetny system Event Streamingowy, świetnie pomaga tworzyć architektury oparte na zdarzeniach, ale póki co nie jest o system Event Sourcingowy - wbrew temu co Confluent próbuje nam wmówić.
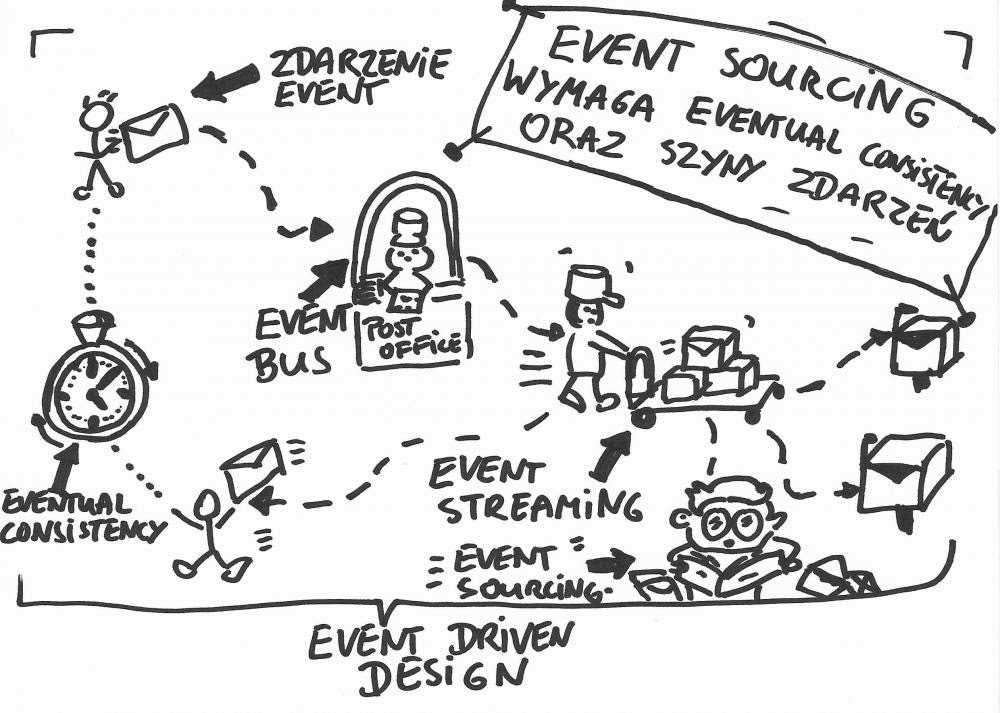
W systemach opartych na zdarzeniach (Event-Driven) wszystkie operacje kończą się lub wywodzą się ze zdarzenia. Przykładowo operacja dodania faktury kończy się zdarzeniem DodanoFakturę, które z kolei może wyzwolić operację wysłania powiadomienia mailowego, wydruku faktury, itd. W systemach tych zdarzenia przetwarzane są na zasadzie kolejki (logu). Przenoszeniem zdarzeń zajmują się systemy streamingowe (Event Streaming) - takie właśnie jak Kafka. Czyli wiedząc, że np. system finansowy produkuje zdarzenie DodanoFakturę wie, że nasłuchuje na nie dwóch konsumentów - system do powiadomień oraz system do wydruków. Systemy streamingowe od zwykłych szyn zdarzeń różni to, że mają one swoją wewnętrzną pamięć by zapewnić, że wysłane zdarzenie nam się nie zgubi gdy np. konsument jest niedostępny (np. chwilowo się zawiesił). Takie systemy dzięki wewnętrznemu przechowywaniu zdarzeń są w stanie automatycznie ponowić zdarzenie gdy konsument wróci do życia.
No i tutaj rodzi się konflikt, bo takie systemy stwierdziły, że skoro one te zdarzenia i tak przechowują to czemu by nie zrobić w nich Event Sourcing. Dla przypomnienia systemy Event Sourcingowe to takie, które na podstawie zdarzeń są w stanie odczytać swój stan. Na zasadzie: daj mi wszystkie zdarzenia dla strumienia (agregatu, encji) o danym id i zaaplikuj je jeden po drugim (tak jak np. transakcje bankowe wy wyliczyć ostateczny stan konta). No i tutaj pojawiają się zgrzyty:
- Kafka sama w sobie nie zapewnia API do pobierania zdarzeń po Id - można to oszukać poprzez np. tworzenie topicu per agregat/encję (jeśli nie wiesz co to topic lub partycja w Kafce daj znać), a partycji per konkretną instancję agregata, ale to tak naprawdę nie załatwia nam tematu, bo partycje też nie są z gumy, mają swój górny limit ile może ich być i przy zwiększonej ich liczbie działa po prostu wolniej,
- Kafka ma retention policy zdarzeń - domyślnie zdarzenia starsze niż tydzień są automatycznie usuwane, więc po tej operacji tracimy stan naszego systemu. Możemy na upartego ustawić sobie czas dłuższy, lub nawet nieskończoność, ale to powoduje znowu spowolnienie działania samej Kafki. Nie jest ona też zoptymalizowana pod przechowywanie danych, ale ich przesyłanie,
- Kafka nie ma dobrych mechanizmów backupów - z automatu Kafka rozprasza swoje dane i ułatwia obsługę sytuacji gdy coś pójdzie nie tak, ale jest to ciągle nastawione na przesył danych, czyli to aby w końcu te zdarzenia były wysyłane. Czyli znowu przesył a nie przechowywanie. Tak naprawdę backupy i restore jeśli chcemy je robić musimy sobie zapewnić sami w jakimś zewnętrznym storage, co nie jest trywialne,
- w Kafce nie jest łatwo zachować kolejność zdarzeń - kolejność zdarzeń jest kluczową sprawą przy odbudowywaniu stanu w systemie event sourcingowym, można sobie poradzić bez niej, ale znacząco komplikuje to życie (i kod). W Kafce im chcemy mieć większą gwarancję zachowania kolejności tym zmniejszamy jej wydajność. Czyli chcąc się zbliżyć do zachowania Event Store’a musimy rezygnować z jej wydajności.
Także koniec końców, czy można zrobić w Kafce Event Sourcing? No jak się uprze i się mega postara to przy pewnych założeniach można, tylko po co? Tak jak zawsze “używaj właściwego narzędzia do właściwej roboty”. Warto zanim zaczniemy używać jakiegoś narzędzia upewnić się czy jest faktycznie do tego co chcemy zrobić stworzony.
Podsumowując systemy Event Sourcingowe z założenia są systemami opartymi o zdarzenia. Z kolei systemy oparte o zdarzenia nie muszą być Event Sourcingowe - równie dobrze mogą przechowywać stan w zwykłych bazach relacyjnych. Każdy zapis oczywiście powinien generować zdarzenie, które potem wyzwolić może inną operację itd. Zdarzenia są przepychane przez systemy Event Streamingoweg takie jak np. Kafka, które po prostu przenoszą je z miejsca na miejsce.
Na koniec podrzucę obrazek z 5 rozdziału mojego Ebooka. Podobno jeden obraz mówi więcej niż ileś tam słów, nie wiem czy w tym wypadku tak jest, ale mam nadzieję, że pomoże jeszcze rozjaśnić temat:
Co o tym sądzisz? Masz jakieś pytania do tego? A może chcesz, żebym któryś fragment rozwinął?
Nie krępuj się pytać, bardzo chętnie odpowiem czy też podyskutuję. W końcu po to jest ten mailing.
Pozdrawiam serdecznie!
Oskar