
Bazy klucz-wartość - o czym warto pamiętać w ich użyciu
Cześć!
Dzisiaj chciałem pomówić trochę o bazach klucz-wartość (Key-Value). Temat na pozór oczywisty, ale przez to łatwo przeoczyć podstawowe założenia i zrobić sobie bubu na produkcji.
Ogólny koncept takich baz jest bardzo prosty. Dane składają się z unikalnej pary - klucza i wartości. Unikalność zapewnia nam klucz, wartość może być czymkolwiek - binarnymi danymi (np. zserializowanymi obiektami lub nawet plikiem wideo), ustrykuryzowanym plikiem tekstowym (JSON, XML), plain tekstem lub inną formą zapisu która przyjdzie nam do głowy - to już zależy od konkretnej implementacji bazy danych.
Takie bazy zaczynają się od bardzo prostych form jak Azure Blob Storage czy też AWS S3 - gdzie wartość nie ma żadnej wyraźnej struktur - to takie worki/wiadra na dane. Co ciekawe w S3 klucz do Twojego zasobu jest unikalny w skali całego świata - nie może się powtórzyć.
Ta unikalność jest bardzo ważna. Z kluczami jest jak z wymyślaniem swojego maila przy jego zakładaniu. Musimy się skupić i wymyśleć wzór, który sprawi, że będzie unikalny. Oczywiście moglibyśmy sobie wygenerować totalnie losowego maila, ale jak ktoś będzie chciał nam coś potem wysłać to będzie miał problem z jego znalezieniem. Wymyślamy więc coś w stylu imię.nazwisko@gmail.com, agusia14@buziaczek.pl czy też inny format, który zapewni nam to, że nasz mail się nie powtórzy. Podobnie z kluczami w bazach klucz-wartość. Aby zapewnić unikalność klucza możemy użyć losowego Guida, możemy też wymyśleć konkretny format np.“NumerKlienta-NumerProjektu-NumerZadania”.
Wbrew pozorom decyzja o wyborze sposobu tworzenia klucza jest kwestią niosiącą za sobą duże konsekwencje. Użycie Guida pozwoli nam z założenia utworzyć unikalną wartość, ale to co musimy pamiętać, to to, że po to zapisujemy wartości, żeby je potem odczytać. Tutaj z Guidem pojawia się problem, bo bardzo słabo się on indeksuje jeśli nie jest wygenerowany przez samą bazę tylko na kliencie. Dlaczego? To wynika właśnie z charakteru jego losowości. Są to wartości zupełnie losowe, więc indeks bazy danych nie będzie mógł wyznaczyć w nim reguły.
Klucze stworzone wobec konkretnego formatu dają tę zaletę, że możemy na ich podstawie zamodelować strukturę drzewiastą - np.:
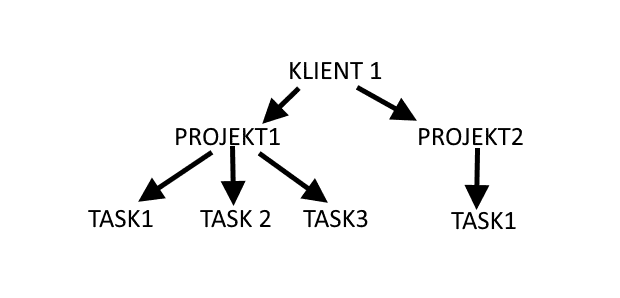
Jak zapewne pamiętasz ze studiów, drzewa mają to do siebie, że bardzo szybko się w nich wyszukuje. Co jest ważne w bazach klucz/wartość. Bo jeśli wartość może być czymkolwiek i może nie posiadać żadnej konkretnej, jednolitej struktury, to z automatu nie będziemy w stanie po nich wyszukiwać. Bo jakby wyglądało wyszukiwanie? W zasadzie musielibyśmy przejść przez wszystkie wartości, pobrać je i sprawdzić czy spełniają nasze kryteria (np. czy zawierają dany fragment tekstu). Dlatego też odpowiednia struktura klucza może nam pozwolić szybko przechodzić i wyszukiwać nasze wartości.
Mając przedstawioną powyżej strukturę klucza “NumerKlienta-NumerProjektu-NumerZadania” bylibyśmy w stanie efektywnie wyszukiwać np. wszystkie projekty dla klientów, lub wszystkie zadania dla danego projektu wybranego klienta.
To wszystko wydaje się bardzo ładne, ale co jakbyśmy chcieli wyszukać wszystkie zadania o numerze 3? Musielibyśmy przejść przez wszystkich klientów i wszystkie projekty i przelecieć się po ich zadaniach. Czyli zrobić znany i nielubiany Full Scan.
Tak, wbrew pozorom bazy klucz-wartość nie są dalekie od baz relacyjnych. De facto klucz-wartość to relacja, krotka. Najprostsza z możliwych. Jak bazy relacyjne radzą sobie z wyszukiwaniem? Tworzą indeksy. Czyli mówią - jeśli szukasz takiej wartości, to te rekordy je mają. To co przyspiesza odczyt - spowalnia zapis. Sporo baz klucz-wartość wspiera w jakiejś formie indeksowanie, ale…
To o czym powinniśmy pamiętać to, że bazy klucz-wartość są najefektywniejsze gdy przechodzimy po strukturze drzewiastej kluczy i jeśli odwołujemy się po konkretnym kluczu. Takie bazy dzięki temu są niesamowicie szybkie bo strzelają do konkretnego miejsca. To takie trochę bazy relacyjne odarte z konieczności bycia zupą pomidorową. Bazy relacyjne można użyć do dowolnej formy zapisu danych, ale mają ten minus, że one wszystko zrobią dobrze, ale czasem dobrze nie wystarcza.
Klucze oparte na strukturze drzewiastej pozwalają też na dużo łatwiejsze partycjonowanie. Czyli wszystkie rozproszone systemy multi region/multi tenant tutaj z tego mogą świetnie skorzystać, bo już sam klucz może pozwolić na odpowiedni “routing” - znalezienie lokalizacji danych. Jeślibyśmy w naszym kluczu dodali np. przedrostek “Kontynent-NazwaDataStore-NumerKlienta-NumerProjektu-NumerZadania”. To na tej podstawie już wiedzielibyśmy konkretnie gdzie strzelić i skąd pobrać dane. Tak też działają właśnie wspomniane Azure Blob Storage czy S3.
No dobrze, a co to są bazy dokumentowe? Bazy dokumentowe, to są bazy klucz-wartość, których wartość mają zdefiniowaną strukturę. Dlatego nazywają się dokumentowe, bo można je porównać do np. wniosku w urzędzie. Mają konkretne pola z konkretnymi możliwymi wartościami. Ta struktura pozwala na efektywniejsze tworzenie kluczy, bo wiemy czego spodziewać się po wartości. Przykłady takich baz to Marten, MongoDB, RavenDB. Możecie zobaczyć jakie opcje daje w Marten posiadanie znanej struktury i Postgresa pod spodem https://martendb.io/documentation/documents/customizing/.
Podobna zasada przyświeca bazą szeroko-kolumnowym (wide column). Jest to krok bliżej do bazy relacyjnej. W takich bazach dalej przechowujemy dane w postaci klucz wartość, ale same wartości przechowywane są w postaci kolumn. Czyli każda wartość to jeden wiersz z kolumnami. Czym się to różni od baz relacyjnych? Tym, że każda wartość może mieć inny zestaw kolumn. Przykłady to Azure Table Storage, Cassandra.
Co ciekawe np. Kafka pod spodem to baza klucz-wartość opakowana algorytmami i technikami do replikacji danych i ustalaniu konsensusu. Redis, Elastic Search to bazy klucz-wartość. Możemy takich baz używać i nawet o tym nie wiedzieć.
Dodatkowo, wbrew pozorom w większości systemów, nad którymi pracujemy nie posiadają danych relacyjnych. Większość z nich jest odzwierciedleniem fizycznego procesu obiegu dokumentów, który nasi klienci chcą przenieść do formy cyfrowej - faktury, zamówienia, bilety, dane osobowe, przywołane już wnioski. Wszystko to są dokumenty.
Dlaczego więc używamy baz relacyjnych? Bo są dobre do zaawansowanego filtrowania, czyli tam gdzie relacje się świetnie sprawdzają.
Czy wiesz, że pierwszy RDBMS został wydany w 1979 roku przez firmę Relational Software - dzisiaj znaną jako Oracle. Dopiero w latach 80tych bazy relacyjne zdobyły swoją popularność. Wcześniej królowały bazy obiektowe. Także bazy NoSQL, nie są żadną nowinką, one są starsze niż bazy relacyjne. To co stanowiło sukces baz relacyjnych to to, że w latach 80tych każdy bit, bajt był na wagę złota - dosłownie. Normalizacja relacyjnych baz danych pozwalała znacząco zmniejszyć wielkość przechowywanych danych. Teraz nie mamy tego problemu, przechowywanie danych jest tanie i nie jest problemem.
Dlatego też przy podejmowaniu decyzji o podejmowaniu decyzji pamiętajmy o podstawach. Sprawdźmy jaki jest charakter przechowywanych przez nas danych. Pamiętajmy, że nie musimy się ograniczać do jednego rodzaju bazy danych. Tam gdzie ma to sens możemy użyć różnych rodzajów dopasowanych do konkretnego problemu.
Zarówno chmury z ich dostępnością różnych silników nam to ułatwiają jak i techniki takie jak CQRS. Może warto np. wykorzystać bazy klucz-wartość do modelu zapisu, a model odczytu w bazie relacyjnej?
Co o tym sądzisz?
Mam nadzieje, że pomogłem!
Pozdrawiam
Oskar